关系型数据库 - NoSQL - 分布式数据库
参考网址:百度搜索 - 数据库
发展现状
数据库先后经历了层次数据库、网状数据库和关系数据库等各个阶段的发展,其中关系型数据库已成为目前数据库产品中最重要的一员,80年代以来,几乎所有的数据库厂商新出的数据库产品都支持关系型数据库,即使一些非关系数据库产品也几乎都有支持关系数据库的接口。这主要是传统的关系型数据库可以比较好的解决管理和存储关系型数据的问题。
随着云计算的发展和大数据时代的到来,由于越来越多的半关系型和非关系型数据需要用数据库进行存储管理,以此同时,分布式技术等新技术的出现也对数据库的技术提出了新的要求,于是越来越多的非关系型数据库就开始出现,这类数据库与传统的关系型数据库在设计和数据结构有了很大的不同,它们更强调数据库数据的高并发读写和存储大数据,这类数据库一般被称为NoSQL(Not only SQL)数据库。但传统的关系型数据库在一些传统领域依然保持了强大的生命力。
关系型数据库
关系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织。常见的关系型数据库有Mysql,SqlServer等。通过外键关联来建立表与表之间的关系。
数据库的SELECT,INSERT,UPDATE,DELETE对应了我们常用的增删改查四种操作。对于结构化数据的处理更合适,如学生成绩、地址等,这样的数据一般情况下需要使用结构化的查询,例如join,
这样的情况下,关系型数据库就会比NoSQL数据库性能更优,而且精确度更高。由于结构化数据的规模不算太大,数据规模的增长通常也是可预期的,所以针对结构化数据使用关系型数据库更好。关系型数据库十分注意数据操作的事务性、一致性,如果对这方面的要求关系型数据库无疑可以很好的满足。

标准SQL语句
虽然关系型数据库有很多,但是大多数都遵循SQL(结构化查询语言,Structured Query Language)标准。常见的操作有查询,新增,更新,删除,求和,排序等。
- 查询语句:SELECT param FROM table WHERE condition 该语句可以理解为从 table 中查询出满足 condition 条件的字段 param。
- 新增语句:INSERT INTO table (param1,param2,param3) VALUES (value1,value2,value3) 该语句可以理解为向table中的param1,param2,param3字段中分别插入value1,value2,value3。
- 更新语句:UPDATE table SET param=new_value WHERE condition 该语句可以理解为将满足condition条件的字段param更新为 new_value 值。 [2]
- 删除语句:DELETE FROM table WHERE condition 该语句可以理解为将满足condition条件的数据全部删除。
- 去重查询:SELECT DISTINCT param FROM table WHERE condition 该语句可以理解为从表table中查询出满足条件condition的字段param,但是param中重复的值只能出现一次。
- 排序查询:SELECT param FROM table WHERE condition ORDER BY param1该语句可以理解为从表table 中查询出满足condition条件的param,并且要按照param1升序的顺序进行排序。
非关系型数据库(NoSQL)
非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。非关系型数据库通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定。非关系型数据库中,我们查询一条数据,结果出来一个数组,关系型数据库中,查询一条数据结果是一个对象。
随着近些年技术方向的不断拓展,大量的NoSql数据库如MongoDB、Redis、Memcache出于简化数据库结构、避免冗余、影响性能的表连接、摒弃复杂分布式的目的被设计。

NoSQL是分布式的、非关系型的、不保证遵循ACID原则的数据存储系统。NoSQL数据库技术与CAP理论、一致性哈希算法有密切关系。
CAP理论:简单来说就是一个分布式系统不可能满足可用性、一致性与分区容错性这三个要求,一次性满足两种要求是该系统的上限。
一致性哈希算:指的是NoSQL数据库在应用过程中,为满足工作需求而在通常情况下产生的一种数据算法,该算法能有效解决工作方面的诸多问题但也存在弊端,即工作完成质量会随着节点的变化而产生波动,当节点过多时,相关工作结果就无法那么准确。这一问题使整个系统的工作效率受到影响,导致整个数据库系统的数据乱码与出错率大大提高,甚至会出现数据节点的内容迁移,产生错误的代码信息。
但尽管如此,NoSQL数据库技术还是具有非常明显的应用优势,如数据库结构相对简单,在大数据量下的读写性能好;能满足随时存储自定义数据格式需求,非常适用于大数据处理工作。
NoSQL数据库适合追求速度和可扩展性、业务多变的应用场景。对于非结构化数据的处理更合适,如文章、评论,这些数据如全文搜索、机器学习通常只用于模糊处理,并不需要像结构化数据一样,进行精确查询,而且这类数据的数据规模往往是海量的,数据规模的增长往往也是不可能预期的,而NoSQL数据库的扩展能力几乎也是无限的,所以NoSQL数据库可以很好的满足这一类数据的存储。NoSQL数据库利用key-value可以大量的获取大量的非结构化数据,并且数据的获取效率很高,但用它查询结构化数据效果就比较差。
NoSQL数据库分类
目前NoSQL数据库仍然没有一个统一的标准,它现在有四种大的分类:
- 键值对存储(key-value):代表软件Redis,它的优点能够进行数据的快速查询,而缺点是需要存储数据之间的关系。
![]()
- 列存储:代表软件Hbase,它的优点是对数据能快速查询,数据存储的扩展性强。而缺点是数据库的功能有局限性。
![]()
- 文档数据库存储:代表软件MongoDB,它的优点是对数据结构要求不特别的严格。而缺点是查询性的性能不好,同时缺少一种统一查询语言。
![]()
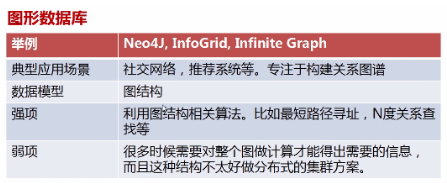
- 图形数据库存储:代表软件InfoGrid,它的优点可以方便的利用图结构相关算法进行计算。而缺点是要想得到结果必须进行整个图的计算,而且遇到不适合的数据模型时,图形数据库很难使用。
![]()



关系型数据库与NoSQL的区别
| 区别 | 关系型数据库 | 非关系型数据库(Nosql) |
|---|---|---|
| 存储方式 | 表格式存储。存储在表的行和列中。他们之间很容易关联协作存储,提取数据很方便 | Nosql数据库则与其相反,他是大块的组合在一起。通常存储在数据集中,就像文档、键值对或者图结构。 |
| 存储结构 | 结构化数据。数据表都预先定义了结构(列的定义),结构描述了数据的形式和内容。这一点对数据建模至关重要,虽然预定义结构带来了可靠性和稳定性(优点),但是修改这些数据比较困难(缺点)。 |
而Nosql数据库基于动态结构,使用非结构化数据。因为Nosql数据库是动态结构,可以很容易适应数据类型和结构的变化。 |
| 存储规范 | 数据存储为了更高的规范性,把数据分割为最小的关系表以避免重复,获得精简的空间利用。虽然管理起来很清晰,但是单个操作设计到多张表的时候,数据管理就显得有点麻烦 | 而Nosql数据存储在平面数据集中,数据经常可能会重复。单个数据库很少被分隔开,而是存储成了一个整体,这样整块数据更加便于读写 |
| 存储扩展 | 系型数据库是纵向扩展,也就是说想要提高处理能力,要使用速度更快的计算机。因为数据存储在关系表中,操作的性能瓶颈可能涉及到多个表,需要通过提升计算机性能来克服。虽然有很大的扩展空间,但是最终会达到纵向扩展的上限 |
而Nosql数据库是横向扩展的,它的存储天然就是分布式的,可以通过给资源池添加更多的普通数据库服务器来分担负载。 |
| 查询方式 | 结构化查询语言来操作数据库(就是我们通常说的SQL),使用关系型数据库表中主键,关系型数据库使用预定义优化方式(比如索引)来加快查询操作 |
以块为单元操作数据,使用的是非结构化查询语言(UnQl),它是没有标准的,使用Nosql中存储文档的D,是更简单更精确的数据访问模式 |
| 事务 | 遵循ACID规则(原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)),支持对事务原子性细粒度控制,并且易于回滚事务。 |
遵循BASE原则(基本可用(Basically Availble)、软/柔性事务(Soft-state )、最终一致性(Eventual Consistency))Nosql数据库是在CAP(一致性、可用性、分区容忍度)中任选两项,因为基于节点的分布式系统中,很难全部满足,所以对事务的支持不是很好,虽然也可以使用事务,但是并不是Nosql的闪光点。 |
| 性能 | 为了维护数据的一致性付出了巨大的代价,读写性能比较差。在面对高并发读写性能非常差,面对海量数据的时候效率非常低。 | Nosql存储的格式都是key-value类型的,并且存储在内存中,非常容易存储,而且对于数据的 一致性是 弱要求。Nosql无需sql的解析,提高了读写性能。 |
| 授权方式 | 关系型数据库通常有SQL Server,Mysql,Oracle。大多数的关系型数据库都是付费的并且价格昂贵,成本较大。 | 主流的Nosql数据库有redis,memcache,MongoDb。Nosql数据库通常都是开源的。 |
关系型数据库与NoSQL优缺点对比
| 类型 | 关系型数据库 SQLite、Oracle、mysql | 非关系型数据库MongoDb、redis、HBase |
|---|---|---|
| 特性 | 1. 关系型数据库,是指采用了关系模型来组织数据的数据库; 2. 关系型数据库的最大特点就是事务的一致性; 3. 简单来说,关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。 |
1. 使用键值对存储数据; 2. 分布式; 3. 一般不支持ACID特性; 4. 非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。 |
| 优点 | 1. 容易理解:二维表结构是非常贴近逻辑世界一个概念,关系模型相对网状、层次等其他模型来说更容易理解; 2. 使用方便:通用的SQL语言使得操作关系型数据库非常方便; 3. 易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率; 4. 复杂操作:支持SQL,可用于一个表以及多个表之间非常复杂的查询。 |
1. 速度快:无需经过sql层的解析,读写性能很高,nosql可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘; 2. 高扩展性:基于键值对,数据没有耦合性,容易扩展; 3. 数据存储格式灵活:nosql的存储格式是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,而关系型数据库则只支持基础类型。 4. 成本低:nosql数据库部署简单,基本都是开源软件。 |
| 缺点 | 1. 为了维护一致性所付出的巨大代价就是其读写性能比较差,尤其是海量数据的高效率读写; 2. 固定的表结构,灵活度稍欠; 3. 高并发读写需求,对于传统关系型数据库来说,硬盘I/O是一个很大的瓶颈; 4. 难以进行海量数据的高效率读写; |
1. 不提供sql支持,学习和使用成本较高; 2. 无事务处理,附加功能bi和报表等支持也不好; |
分布式数据库
所谓的分布式数据库技术,就是结合了数据库技术与分布式技术的一种结合。具体指的是把那些在地理意义上分散开的各个数据库节点,但在计算机系统逻辑上又是属于同一个系统的数据结合起来的一种数据库技术。既有着数据库间的协调性也有着数据的分布性。这个系统并不注重系统的集中控制,而是注重每个数据库节点的自治性,此外为了让程序员能够在编写程序时可以减轻工作量以及系统出错的可能性,一般都是完全不考虑数据的分布情况,这样的结果就使得系统数据的分布情况一直保持着透明性。
数据独立性概念在分布式数据库管理系统中同样是十分重要的一环,但是不仅如此,分布式数据管理系统还增加了一个叫分布式透明性的新概念。这个新概念的作用是让数据进行转移时使程序正确性不受影响,就像数据并没有在编写程序时被分布一样。
在分布式数据库里,数据冗杂是一种被需要的特性,这点和一般的集中式数据库系统不一样。第一点是为了提高局部的应用性而要在那些被需要的数据库节点复制数据。第二点是因为如果某个数据库节点出现系统错误,在修复好之前,可以通过操作其他的数据库节点里复制好的数据来让系统能够继续使用,提高系统的有效性。
数据库常见面试知识总结
这里是一些面试相关时数据库相关知识
参考网址:Github - 面试基础知识总结
本节部分知识点来自《数据库系统概论(第 5 版)》
基本概念
- 数据(data):描述事物的符号记录称为数据。
- 数据库(DataBase,DB):是长期存储在计算机内、有组织的、可共享的大量数据的集合,具有永久存储、有组织、可共享三个基本特点。
- 数据库管理系统(DataBase Management System,DBMS):是位于用户与操作系统之间的一层数据管理软件。
- 数据库系统(DataBase System,DBS):是有数据库、数据库管理系统(及其应用开发工具)、应用程序和数据库管理员(DataBase Administrator DBA)组成的存储、管理、处理和维护数据的系统。
- 属性(attribute):实体所具有的某一特性称为属性。
- 码(key):唯一标识实体的属性集称为码。
- 实体(entity):客观存在并可相互区别的事物称为实体。
- 实体(类)型(entity type):用实体名及其属性名集合来抽象和刻画同类实体,称为实体(类)型。
- 实体集(entity set):同一实体型的集合称为实体集。
- 联系(relationship):实体之间的联系通常是指不同实体集之间的联系。
- 模式(schema):模式也称逻辑模式,是数据库全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。
- 外模式(external schema):外模式也称子模式(subschema)或用户模式,它是数据库用户(包括应用程序员和最终用户)能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。
- 内模式(internal schema):内模式也称为存储模式(storage schema),一个数据库只有一个内模式。他是数据物理结构和存储方式的描述,是数据库在数据库内部的组织方式。
常用数据模型
- 层次模型(hierarchical model)
- 网状模型(network model)
- 关系模型(relational model)
- 关系(relation):一个关系对应通常说的一张表
- 元组(tuple):表中的一行即为一个元组
- 属性(attribute):表中的一列即为一个属性
- 码(key):表中可以唯一确定一个元组的某个属性组
- 域(domain):一组具有相同数据类型的值的集合
- 分量:元组中的一个属性值
- 关系模式:对关系的描述,一般表示为
关系名(属性1, 属性2, ..., 属性n)
- 面向对象数据模型(object oriented data model)
- 对象关系数据模型(object relational data model)
- 半结构化数据模型(semistructure data model)
常用 SQL 操作
| 对象类型 | 对象 | 操作类型 |
|---|---|---|
| 数据库模式 | 模式 | CREATE SCHEMA |
| 基本表 | CREATE SCHEMA,ALTER TABLE |
|
| 视图 | CREATE VIEW |
|
| 索引 | CREATE INDEX |
|
| 数据 | 基本表和视图 | SELECT,INSERT,UPDATE,DELETE,REFERENCES,ALL PRIVILEGES |
| 属性列 | SELECT,INSERT,UPDATE,REFERENCES,ALL PRIVILEGES |
SQL 语法教程:菜鸟Runoob - SQL 教程
DB2 教程:易百 - DB2 教程
关系型数据库
基本关系操作:查询(选择、投影、连接(等值连接、自然连接、外连接(左外连接、右外连接))、除、并、差、交、笛卡尔积等)、插入、删除、修改
关系模型中的三类完整性约束:实体完整性、参照完整性、用户定义的完整性。
- 实体完整性:要求每个数据表都必须有主键,而作为主键的所有字段,其属性必须是独一及非空值。
- 参照完整性:相关联的两个表之间的约束,要求关系中不允许引用不存在的实体。
- 用户定义的完整性:用户自定义完整性是针对某一具体关系数据库的约束条件,它反映某一具体应用所涉及的数据必须满足的语义要求。主要包括非空约束、唯一约束、检查约束、主键约束、外键约束
索引
数据库索引:顺序索引、B+ 树索引、hash 索引
数据库完整性
- 数据库的完整性是指数据的正确性和相容性。
- 完整性:为了防止数据库中存在不符合语义(不正确)的数据。
- 安全性:为了保护数据库防止恶意破坏和非法存取。
- 触发器:是用户定义在关系表中的一类由事件驱动的特殊过程。
关系数据理论
- 数据依赖是一个关系内部属性与属性之间的一种约束关系,是通过属性间值的相等与否体现出来的数据间相关联系。
- 最重要的数据依赖:函数依赖、多值依赖。
范式
- 第一范式(1NF):属性(字段)是最小单位不可再分。
- 第二范式(2NF):满足 1NF,每个非主属性完全依赖于主键(消除 1NF 非主属性对码的部分函数依赖)。
- 第三范式(3NF):满足 2NF,任何非主属性不依赖于其他非主属性(消除 2NF 主属性对码的传递函数依赖)。
- 鲍依斯-科得范式(BCNF):满足 3NF,任何非主属性不能对主键子集依赖(消除 3NF 主属性对码的部分和传递函数依赖)。
- 第四范式(4NF):满足 3NF,属性之间不能有非平凡且非函数依赖的多值依赖(消除 3NF 非平凡且非函数依赖的多值依赖)。
数据库恢复
- 事务:是用户定义的一个数据库操作序列,这些操作要么全做,要么全不做,是一个不可分割的工作单位。
- 事物的 ACID 特性:原子性、一致性、隔离性、持续性。
- 恢复的实现技术:建立冗余数据 -> 利用冗余数据实施数据库恢复。
- 建立冗余数据常用技术:数据转储(动态海量转储、动态增量转储、静态海量转储、静态增量转储)、登记日志文件。
并发控制
- 事务是并发控制的基本单位。
- 并发操作带来的数据不一致性包括:丢失修改、不可重复读、读 “脏” 数据。
- 并发控制主要技术:封锁、时间戳、乐观控制法、多版本并发控制等。
- 基本封锁类型:排他锁(X 锁 / 写锁)、共享锁(S 锁 / 读锁)。
- 活锁死锁:
- 活锁:事务永远处于等待状态,可通过先来先服务的策略避免。
- 死锁:事物永远不能结束
- 预防:一次封锁法、顺序封锁法;
- 诊断:超时法、等待图法;
- 解除:撤销处理死锁代价最小的事务,并释放此事务的所有的锁,使其他事务得以继续运行下去。
- 可串行化调度:多个事务的并发执行是正确的,当且仅当其结果与按某一次序串行地执行这些事务时的结果相同。可串行性时并发事务正确调度的准则。
常见大型数据库
参考网址:常用大型数据库比较
目前商品化的数据库管理系统以关系型数据库为主导产品,技术比较成熟。国际国内的主导关系型数据库管理系统有ORACLE、SYBASE、INFORMIX和INGRES。这些产品都支持多平台,如UNIX、VMS、 WINDOWS,但支持的程度不一样。
IBM 的 DB2 也是成熟的关系型数据库。但是,DB2是内嵌于IBM的 AS/400系列机中,只支持OS/400操作系统。
根据选择数据库管理系统的依据,我们比较、分析一下这几种数据库管理系统的性能:
ORACLE数据库管理系统
- 无范式要求,可根据实际系统需求构造数据库。
- 采用标准的SQL结构化查询语言。
- 具有丰富的开发工具,覆盖开发周期的各阶段。
- 支持大型数据库,数据类型支持数字、字符、大至2GB的二进制数
据,为数据库的面向对象存储提供数据支持。 - 具有第四代语言的开发工具(SQLFORMS、SQLREPORTS、SQL*MENU等)。
- 具有字符界面和图形界面,易于开发。ORACLE7。1版本具有面
向对象的开发环境CDE2。 - 通过SQL*DBA控制用户权限,提供数据保护功能,监控数据库的
运行状态,调整数据缓冲区的大小。 - 分布优化查询功能。
- 具有数据透明、网络透明,支持异种网络、异构数据库系统。并行
处理采用动态数据分片技术。 - 支持客户机/服务器体系结构及混合的体系结构(集中式、分布式、
客户机/服务器)。 - 实现了两阶段提交、多线索查询手段。
- 支持多种系统平台(HPUX、SUNOS、OSF/1、VMS、
WINDOWS、WINDOWS/NT、OS/2)。 - 数据安全保护措施:没有读锁,采取快照SNAP方式完全消除了分
布读写冲突。自动检测死锁和冲突并解决。 - 数据安全级别为C2级(最高级)。
- 数据库内模支持多字节码制,支持多种语言文字编码。
- 具有面向制造系统的管理信息系统和财务系统应用系统。
- ORACLE7。1版本服务器支持1000—10000个用户。
WORKGROUP/2000具有ORACLE7WORKGROUP服务器,
POWER OBJECTS(图形开发环境,支持OS/2、UNIX、 WINDOWS/NT平台。 - 在中国的销售份额占50%以上。
DB2数据库管理系统
DB2是内嵌于IBM的AS/400系统上的数据库管理系统,直接由硬件支持。它支持标准的SQL语言,具有与异种数据库相连的GATEWAY。因此它具有速度快、可靠性好的优点。
但是,只有硬件平台选择了IBM的AS/400,才能选择使用DB2数据库管理系统。
SYBASE 10 数据库管理系统
SYBASE数据库系统从1992年11月开始开发,历经12 — 24个月的开发形成产品,产品包括:SQL SERVER 10(数据库管理系统的核心),REPLICATION SERVER(实现数据库分布的服务器),BACKUP SERVER(网络环境下的快速备份服务器),OMINI SQL GATEWAY(异构数据库库关), NAVIGATION SERVER(网络上可扩充的并行处理能力服务器),CONTROL SERVER(数据库管理员服务器)。属于客户机/服务器体系结构,提供了在网络环境下的各节点上的数据库数据的互访。
SYBASE的技术特点
- 完全的客户机/服务器体系结构,能适应OLTP(ON—LINE
TRANSACTION PROCESSING)要求,能为数百用户提供高性能需求。 - 采用单进程多线索(SINGLE PORCESS AND MULTI—THREADED)
技术进行查询,节省系统开销,提高内存的利用率。 - 支持存储过程,客户只需通过网络发出执行请求,就可马
上执行,有效地加快了数据库访问速度,明显减少网络通讯量,
有可能极大的改善网络环境的运行效率,增加数据库的服务容量。 - 虚服务器体系结构与对称多处理器(SMP)技术结合,充分发
挥多CPU硬件平台的高性能。 - 数据库管理系统DBA在线调整监控数据库系统的性能。
- 提供日志与数据库的镜象,提高数据库容错能力。
- 支持计算机蔟族(CLUSTER)环境下的快速故障切换。
- 通过存储和触发器(TRIGGER)由服务器制约数据的完整性。
- 多种安全机制对表、视图、存储过程、命令进行授权。
- 分布式事务处理采用2PC(TWO PHASE COMMIT)技术访问
- 支持IMAGE和TEXT的数据类型,为工程数据库和多媒体应
用提供了良好的基础。
SYBASE的开发工具
- DATA WORKBENCH
- VISUAL QUERY LANGUANGE(图形查询语言)
- REPORT WORKBENCH(报表系统)
- INTERACTIVE SQL(交互式SQL环境)
- DATA ENTRY(快速录入数据)
APT WORKBENCH
EMBEDED SQL - SQR WORKBENCH(开放式报表系统)
- EASY SQR(基于菜单的报表生成器)
- SQR 4GL(第四代语言报表生成器)
- SQR DEBUG(调试工具)
- SQL—EXECUTE(动态表格配置)
GAIN MOMENTUM(面向对象的多媒体开发平台,可以
编辑动画、声音、位图)
SYBASE的不足
- 多服务器系统不支持分布透明
- REPLICATION SERVER数据方面的性能较差,并不能
与操作系统集成 - 对中文的支持较差
- 多用于银行系统等
- 尚无在此数据库基础上的企业管理信息系统
INGRES智能关系性数据库管理系统
INGRES数据库系统的多项技术直接采用了伯克利大学最新研究成果。技术上一直处于领先水平。INGRES数据库不仅能管理数据,而且还能管理知识和对象(对象是指数据与操作的结合体,计算机把他们作为整体处理)。
INGRES产品分为三类:第一类为数据库基本系统,包括了数据管理、知识管理、和对象管理。第二类为开发工具。第三类为开放互联产品。
INGRES的特点
- 开放的客户机/服务器体系结构,允许用户建立多个多线索服务器。
- 编译的数据库过程。数据库过程用INGRES第四代语言编
写。由服务器编译管理,用来实现预定义的事务处理,减小CPU负载,减小网络开销。 - 智能优化功能。根据查询语言的要求自动地在网络环境中调 整查询顺序,寻找最佳路径。
- 数据的在线备份。无需中断系统的正常运行,备份保持一致性的数据库备份。
- I/O减量处理。提供快速提交、成组提交、多块读出与写入的技术。减少I/O量。
- 多文件存储数据。一个表用一个文件存储,便于在异常情况下对数据库存进行恢复。
- 采用两阶段提交协议,保证了网络分布事务的一致性。
- 具有数据库规则系统。自动激活满足行为条件的规则,对每个表拥有的独立规则数不受限制,
- 无限制的向前推理和无限递归,确保数据库的一致性。
- 具有报警系统,当数据在规定的数据量极限时,自动作出相应的操作。
- 资源控制与查询优化相结合,由服务器控制查询的资源消耗,确保系统的可预测性能。
- 能够对用户自己定义的数据类型进行处理、存储,定义数据的有效区间。
- 允许用户将自己定义的函数嵌入到数据库管理系统中。
INGRES的开发工具
- INGRES/WINDOWS 4GL,该工具通过面向对象的第四代语言和调试器,提高程序员的生产率。支持MICROSOFT WINDOWS、OPEN LOOK、DECWIN等窗口环境。
- INGRES/VISION。是应用代码生成器,包括支持高级界面特征(应用结构的图形表示、菜单驱动、在线HELP、有效数据的动态选择)。还允许用户调整生成的代码。用户决策支持工具。包括GQL(GRAPHIC QUERY LANGUAGE)、GRAFSMAN、IPM(INTERACTIVE PERFORMANCE MONITOR
- INGRES/NET,是一种基于全局通信体系结构,能与OSI兼容的客户机/服务器通信协议。支持诗句的透明性、网络的透明性、多平台透明性。
- INGRE/STAR,是一种分布信息管理机制,他允许用户将分布在不同场地的数据库视为整体,为分布式数据库提供多数据库存的集成、分布数据字典、分布 查询优化、分布处理。
- INGRES/GATEWAY,非INGRES数据库系统与INGRES数据库互联产品。
- INGRES ENHANCED SECURITY增强保安系统,按美国B1 安全指标设计的安全系统,满足数据一致性、可用性、可信性要求,具有行层标签、底层多层安全系统、安全标签数据类型和复杂的一致性机制。
INGRES的不足
学术价值大于实用价值。即在学术方面掌握领先技术,在产品服务上比较薄弱。
INFORMIX数据库管理系统
INFORMIX运行在UNIX平台,支持SUNOS、HPUX、 ALFAOSF/1。采用双引擎机制,占用资源小,简单易用。适用于中小型数据库管理。
INFORMIX的特点
- DSA(DYMANIC SCALABLE ARCHITECTURE)动态可调整结构支持SMP查询语句
- 多线索查询机制
- 具有三个任务队列
- 具有虚拟处理器
- 提供并行索引功能,是高性能的OLTP数据库
- 数据物理结构为静态分片
- 支持双机簇族(CLUSTER)(只支持SESQUENT 平台)
- 具有对复杂系统应用开发的INFORMIX 4GL CADE工具
INFORMIX的主要产品
- INFORMIX—SE
- INFORMIX—ONLINE
- INFORMIX—SQL
- INFORMIX—4GL
- INFORMIX—OPEN CASE/TOOL BUS
- INFORMIX—VIEW POINT
- INFORMIX—STAR
- INFORMIX—NET
- INFORMIX—GATEWAY
INFORMIX的不足
- 网络性能不好,不支持异种网络。即只支持数据透明不支持网络透明。
- 并发控制易死锁。
- 数据备份具有软件镜象功能,速度慢、可靠性差。
- 对大型数据库系统不能得到很好的性能。
- 开发工具不成熟,只具有字符界面,多媒体数据弱,无覆盖全开发过程的CASE工具。
- 无CLIENT/SERVER分布式处理模式
- 可移植性差,不同版本的数据结构不兼容。
- 4GL与CADE的代码不可移植。


